Exogenous variables (features)¶
Exogenous variables are predictors that are independent of the model being used for forecasting, and their future values must be known in order to include them in the prediction process. The inclusion of exogenous variables can enhance the accuracy of forecasts.
In Skforecast, exogenous variables can be easily included as predictors in all forecasting models. To ensure that their effects are accurately accounted for, it is crucial to include these variables during both the training and prediction phases. This will help to optimize the accuracy of forecasts and provide more reliable predictions.
✎ Note
When exogenous variables are used, their values must be aligned so that y[i] regresses on exog[i].
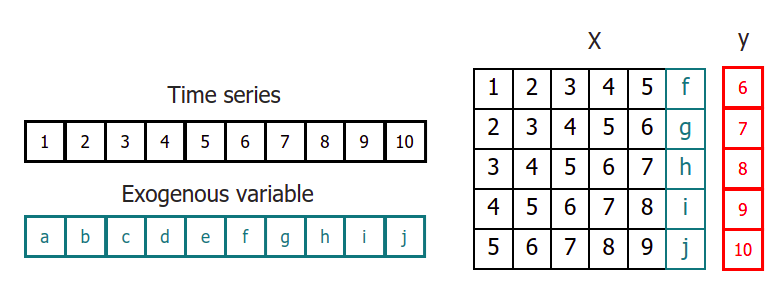
Time series transformation including an exogenous variable.
⚠ Warning
When exogenous variables are included in a forecasting model, it is assumed that all exogenous inputs are known in the future. Do not include exogenous variables as predictors if their future value will not be known when making predictions.
✎ Note
For a detailed guide on how to include categorical exogenous variables, please visit Categorical Features.
Libraries¶
# Libraries
# ==============================================================================
import pandas as pd
import matplotlib.pyplot as plt
from skforecast.ForecasterAutoreg import ForecasterAutoreg
from skforecast.datasets import fetch_dataset
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
Data¶
# Download data
# ==============================================================================
data = fetch_dataset(name='h2o_exog', raw=False)
data.index.name = 'datetime'
# Plot
# ==============================================================================
fig, ax=plt.subplots(figsize=(7, 3.5))
data.plot(ax=ax);
h2o_exog -------- Monthly expenditure ($AUD) on corticosteroid drugs that the Australian health system had between 1991 and 2008. Two additional variables (exog_1, exog_2) are simulated. Hyndman R (2023). fpp3: Data for Forecasting: Principles and Practice (3rd Edition). http://pkg.robjhyndman.com/fpp3package/, https://github.com/robjhyndman/fpp3package, http://OTexts.com/fpp3. Shape of the dataset: (195, 3)

# Split data in train and test
# ==============================================================================
steps = 36
data_train = data.iloc[:-steps, :]
data_test = data.iloc[-steps:, :]
Train forecaster¶
# Create and fit forecaster
# ==============================================================================
forecaster = ForecasterAutoreg(
regressor = RandomForestRegressor(random_state=123),
lags = 15
)
forecaster.fit(
y = data_train['y'],
exog = data_train[['exog_1', 'exog_2']]
)
forecaster
=================
ForecasterAutoreg
=================
Regressor: RandomForestRegressor(random_state=123)
Lags: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
Transformer for y: None
Transformer for exog: None
Window size: 15
Weight function included: False
Differentiation order: None
Exogenous included: True
Type of exogenous variable: <class 'pandas.core.frame.DataFrame'>
Exogenous variables names: ['exog_1', 'exog_2']
Training range: [Timestamp('1992-04-01 00:00:00'), Timestamp('2005-06-01 00:00:00')]
Training index type: DatetimeIndex
Training index frequency: MS
Regressor parameters: {'bootstrap': True, 'ccp_alpha': 0.0, 'criterion': 'squared_error', 'max_depth': None, 'max_features': 1.0, 'max_leaf_nodes': None, 'max_samples': None, 'min_impurity_decrease': 0.0, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'monotonic_cst': None, 'n_estimators': 100, 'n_jobs': None, 'oob_score': False, 'random_state': 123, 'verbose': 0, 'warm_start': False}
fit_kwargs: {}
Creation date: 2024-05-14 20:34:19
Last fit date: 2024-05-14 20:34:19
Skforecast version: 0.12.0
Python version: 3.11.8
Forecaster id: None
Prediction¶
If the Forecaster has been trained using exogenous variables, they should be provided during the prediction phase.
# Predict
# ==============================================================================
steps = 36
predictions = forecaster.predict(
steps = steps,
exog = data_test[['exog_1', 'exog_2']]
)
predictions.head(3)
2005-07-01 0.908832 2005-08-01 0.953925 2005-09-01 1.100887 Freq: MS, Name: pred, dtype: float64
# Plot predictions
# ==============================================================================
fig, ax=plt.subplots(figsize=(7, 3.5))
data_train['y'].plot(ax=ax, label='train')
data_test['y'].plot(ax=ax, label='test')
predictions.plot(ax=ax, label='predictions')
ax.legend();

# Prediction error
# ==============================================================================
error_mse = mean_squared_error(
y_true = data_test['y'],
y_pred = predictions
)
print(f"Test error (MSE): {error_mse}")
Test error (MSE): 0.004022228812838391
Feature importances¶
If exogenous variables are included as predictors, they have a value of feature importances.
# Feature importances with exogenous variables
# ==============================================================================
forecaster.get_feature_importances()
| feature | importance | |
|---|---|---|
| 11 | lag_12 | 0.773389 |
| 1 | lag_2 | 0.061120 |
| 16 | exog_2 | 0.044616 |
| 9 | lag_10 | 0.020587 |
| 13 | lag_14 | 0.018127 |
| 0 | lag_1 | 0.013354 |
| 15 | exog_1 | 0.010364 |
| 8 | lag_9 | 0.010319 |
| 2 | lag_3 | 0.009086 |
| 14 | lag_15 | 0.008732 |
| 7 | lag_8 | 0.008154 |
| 10 | lag_11 | 0.007036 |
| 12 | lag_13 | 0.004583 |
| 5 | lag_6 | 0.003155 |
| 3 | lag_4 | 0.002721 |
| 4 | lag_5 | 0.002478 |
| 6 | lag_7 | 0.002179 |
Backtesting with exogenous variables¶
All the backtesting strategies available in skforecast can also be applied when incorporating exogenous variables in the forecasting model. Visit the Backtesting section for more information.