Recursive multi-step forecasting¶
Recursive multi-step forecasting involves using the predicted values from previous time steps as input to forecast the values for the subsequent time steps. The model initially predicts one time step ahead and then uses that forecast as an input for the next time step, continuing this recursive process until the desired forecast horizon is reached.
To clarify, since the value of is required to predict , and is unknown, a recursive process is applied in which, each new prediction is based on the previous one.
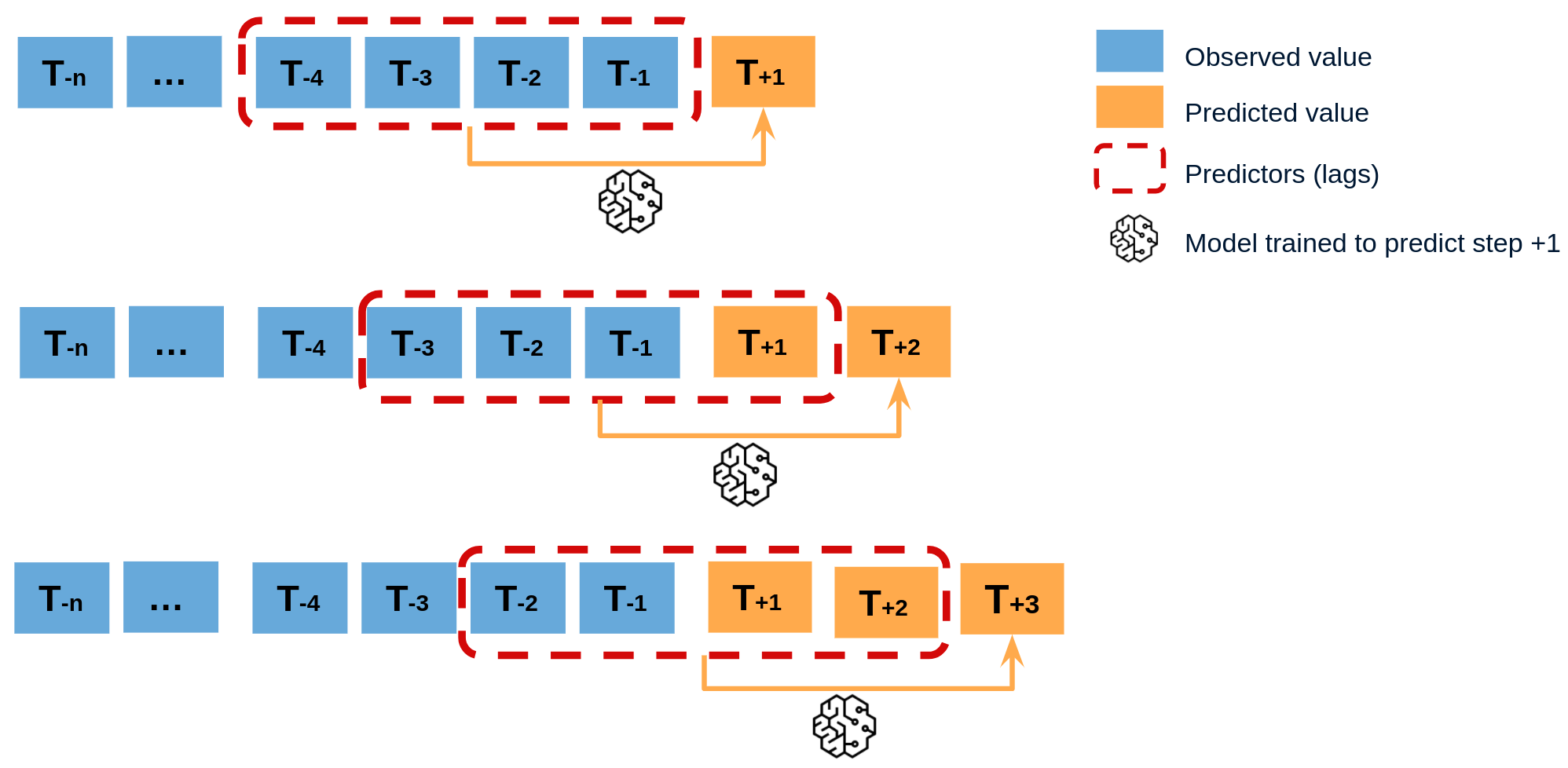
Diagram of recursive multi-step forecasting.
When using machine learning models for recursive multi-step forecasting, one of the major challenges is transforming the time series data into a matrix format that relates each value of the series to the preceding time window (lags). This process can be complex and time-consuming, requiring careful feature engineering to ensure the model can accurately capture the underlying patterns in the data.
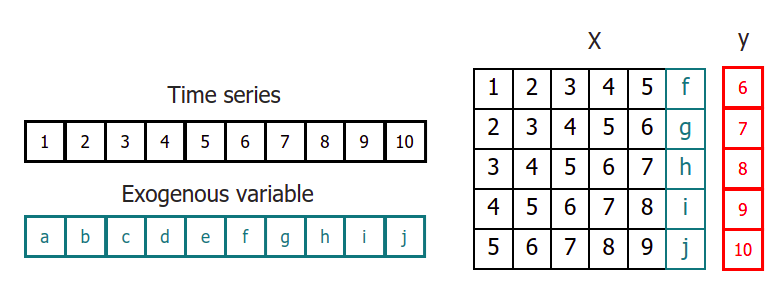
Time series transformation including an exogenous variable.
By using the classes ForecasterAutoreg and ForecasterAutoregCustom, it is possible to build machine learning models for recursive multi-step forecasting with ease. These classes can automatically transform the time series data into a matrix format suitable for input to a machine learning algorithm, and provide a range of options for tuning the model parameters to achieve the best possible performance.
Libraries¶
# Libraries
# ==============================================================================
import pandas as pd
import matplotlib.pyplot as plt
from skforecast.ForecasterAutoreg import ForecasterAutoreg
from skforecast.datasets import fetch_dataset
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
Data¶
# Download data
# ==============================================================================
data = fetch_dataset(
name="h2o", raw=True, kwargs_read_csv={"names": ["y", "datetime"], "header": 0}
)
# Data preprocessing
# ==============================================================================
data['datetime'] = pd.to_datetime(data['datetime'], format='%Y-%m-%d')
data = data.set_index('datetime')
data = data.asfreq('MS')
data = data['y']
data = data.sort_index()
# Split train-test
# ==============================================================================
steps = 36
data_train = data[:-steps]
data_test = data[-steps:]
# Plot
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 3))
data_train.plot(ax=ax, label='train')
data_test.plot(ax=ax, label='test')
ax.legend();
h2o --- Monthly expenditure ($AUD) on corticosteroid drugs that the Australian health system had between 1991 and 2008. Hyndman R (2023). fpp3: Data for Forecasting: Principles and Practice(3rd Edition). http://pkg.robjhyndman.com/fpp3package/,https://github.com/robjhyndman /fpp3package, http://OTexts.com/fpp3. Shape of the dataset: (204, 2)

Create and train forecaster¶
# Create and fit forecaster
# ==============================================================================
forecaster = ForecasterAutoreg(
regressor = RandomForestRegressor(random_state=123),
lags = 15
)
forecaster.fit(y=data_train)
forecaster
=================
ForecasterAutoreg
=================
Regressor: RandomForestRegressor(random_state=123)
Lags: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
Transformer for y: None
Transformer for exog: None
Window size: 15
Weight function included: False
Differentiation order: None
Exogenous included: False
Type of exogenous variable: None
Exogenous variables names: None
Training range: [Timestamp('1991-07-01 00:00:00'), Timestamp('2005-06-01 00:00:00')]
Training index type: DatetimeIndex
Training index frequency: MS
Regressor parameters: {'bootstrap': True, 'ccp_alpha': 0.0, 'criterion': 'squared_error', 'max_depth': None, 'max_features': 1.0, 'max_leaf_nodes': None, 'max_samples': None, 'min_impurity_decrease': 0.0, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'monotonic_cst': None, 'n_estimators': 100, 'n_jobs': None, 'oob_score': False, 'random_state': 123, 'verbose': 0, 'warm_start': False}
fit_kwargs: {}
Creation date: 2024-05-13 12:40:49
Last fit date: 2024-05-13 12:40:49
Skforecast version: 0.12.0
Python version: 3.11.8
Forecaster id: None
Prediction¶
# Predict
# ==============================================================================
predictions = forecaster.predict(steps=36)
predictions.head(3)
2005-07-01 0.921840 2005-08-01 0.954921 2005-09-01 1.101716 Freq: MS, Name: pred, dtype: float64
# Plot predictions
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 3))
data_train.plot(ax=ax, label='train')
data_test.plot(ax=ax, label='test')
predictions.plot(ax=ax, label='predictions')
ax.legend();

# Prediction error
# ==============================================================================
error_mse = mean_squared_error(
y_true = data_test,
y_pred = predictions
)
print(f"Test error (mse): {error_mse}")
Test error (mse): 0.00429855684785846
Prediction intervals¶
A prediction interval defines the interval within which the true value of y is expected to be found with a given probability. For example, the prediction interval (1, 99) can be expected to contain the true prediction value with 98% probability.
By default, every forecaster can estimate prediction intervals using the method predict_interval. For a detailed explanation of the different prediction intervals available in skforecast visit Probabilistic forecasting.
# Predict intervals
# ==============================================================================
predictions = forecaster.predict_interval(steps=36, interval=[5, 95], n_boot=100)
predictions.head(3)
| pred | lower_bound | upper_bound | |
|---|---|---|---|
| 2005-07-01 | 0.921840 | 0.881507 | 0.965114 |
| 2005-08-01 | 0.954921 | 0.922948 | 0.986188 |
| 2005-09-01 | 1.101716 | 1.061478 | 1.143415 |
# Plot prediction interval
# ==============================================================================
fig, ax = plt.subplots(figsize=(6, 3))
data_test.plot(ax=ax, label="test")
predictions['pred'].plot(ax=ax, label="prediction")
ax.fill_between(
predictions.index,
predictions['lower_bound'],
predictions['upper_bound'],
color = 'blue',
alpha = 0.3,
label = '80% interval'
)
ax.legend(loc="upper left");

Feature importances¶
forecaster.get_feature_importances()
| feature | importance | |
|---|---|---|
| 11 | lag_12 | 0.807098 |
| 1 | lag_2 | 0.085160 |
| 13 | lag_14 | 0.016328 |
| 2 | lag_3 | 0.013407 |
| 9 | lag_10 | 0.012751 |
| 0 | lag_1 | 0.012340 |
| 14 | lag_15 | 0.009979 |
| 10 | lag_11 | 0.009019 |
| 8 | lag_9 | 0.007831 |
| 7 | lag_8 | 0.007141 |
| 12 | lag_13 | 0.004811 |
| 3 | lag_4 | 0.004374 |
| 5 | lag_6 | 0.003436 |
| 4 | lag_5 | 0.003188 |
| 6 | lag_7 | 0.003136 |
Extract training matrices¶
To examine how data is being transformed, it is possible to use the create_train_X_y method to generate the matrices that the forecaster is using to train the model. This approach enables gaining insight into the specific data manipulations that occur during the training process.
# Create training matrices
# ==============================================================================
X_train, y_train = forecaster.create_train_X_y(data_train)
X_train.head()
| lag_1 | lag_2 | lag_3 | lag_4 | lag_5 | lag_6 | lag_7 | lag_8 | lag_9 | lag_10 | lag_11 | lag_12 | lag_13 | lag_14 | lag_15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| datetime | |||||||||||||||
| 1992-10-01 | 0.534761 | 0.475463 | 0.483389 | 0.410534 | 0.361801 | 0.379808 | 0.351348 | 0.336220 | 0.660119 | 0.602652 | 0.502369 | 0.492543 | 0.432159 | 0.400906 | 0.429795 |
| 1992-11-01 | 0.568606 | 0.534761 | 0.475463 | 0.483389 | 0.410534 | 0.361801 | 0.379808 | 0.351348 | 0.336220 | 0.660119 | 0.602652 | 0.502369 | 0.492543 | 0.432159 | 0.400906 |
| 1992-12-01 | 0.595223 | 0.568606 | 0.534761 | 0.475463 | 0.483389 | 0.410534 | 0.361801 | 0.379808 | 0.351348 | 0.336220 | 0.660119 | 0.602652 | 0.502369 | 0.492543 | 0.432159 |
| 1993-01-01 | 0.771258 | 0.595223 | 0.568606 | 0.534761 | 0.475463 | 0.483389 | 0.410534 | 0.361801 | 0.379808 | 0.351348 | 0.336220 | 0.660119 | 0.602652 | 0.502369 | 0.492543 |
| 1993-02-01 | 0.751503 | 0.771258 | 0.595223 | 0.568606 | 0.534761 | 0.475463 | 0.483389 | 0.410534 | 0.361801 | 0.379808 | 0.351348 | 0.336220 | 0.660119 | 0.602652 | 0.502369 |
y_train.head()
datetime 1992-10-01 0.568606 1992-11-01 0.595223 1992-12-01 0.771258 1993-01-01 0.751503 1993-02-01 0.387554 Freq: MS, Name: y, dtype: float64
Prediction on training data¶
While the main focus of creating forecasting models is predicting future values, it's also useful to evaluate whether the model is learning from the training data. Predictions on the training data can help with this evaluation.
To obtain predictions on the training data, the predict() method of the regressor stored inside the forecaster object can be accessed, and the training matrix can be passed as an input to this method. By examining the predictions on the training data, analysts can get a better understanding of how the model is performing and make adjustments as necessary.
# Create training matrices
# ==============================================================================
X_train, y_train = forecaster.create_train_X_y(data_train)
# Predict using the internal regressor
# ==============================================================================
predictions_training = forecaster.regressor.predict(X_train)
predictions_training[:4]
array([0.55271468, 0.56539424, 0.72799541, 0.73649315])
Differentiation¶
Time series differentiation involves computing the differences between consecutive observations in the time series. When it comes to training forecasting models, differentiation offers the advantage of focusing on relative rates of change rather than directly attempting to model the absolute values. Once the predictions have been estimated, this transformation can be easily reversed to restore the values to their original scale.
💡 Tip
To learn more about modeling time series differentiation, visit our example: Modelling time series trend with tree based models.
# Create and fit forecaster
# ==============================================================================
forecaster = ForecasterAutoreg(
regressor = RandomForestRegressor(random_state=123),
lags = 15,
differentiation = 1
)
forecaster.fit(y=data_train)
forecaster
=================
ForecasterAutoreg
=================
Regressor: RandomForestRegressor(random_state=123)
Lags: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
Transformer for y: None
Transformer for exog: None
Window size: 15
Weight function included: False
Differentiation order: 1
Exogenous included: False
Type of exogenous variable: None
Exogenous variables names: None
Training range: [Timestamp('1991-07-01 00:00:00'), Timestamp('2005-06-01 00:00:00')]
Training index type: DatetimeIndex
Training index frequency: MS
Regressor parameters: {'bootstrap': True, 'ccp_alpha': 0.0, 'criterion': 'squared_error', 'max_depth': None, 'max_features': 1.0, 'max_leaf_nodes': None, 'max_samples': None, 'min_impurity_decrease': 0.0, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'monotonic_cst': None, 'n_estimators': 100, 'n_jobs': None, 'oob_score': False, 'random_state': 123, 'verbose': 0, 'warm_start': False}
fit_kwargs: {}
Creation date: 2024-05-13 12:41:12
Last fit date: 2024-05-13 12:41:12
Skforecast version: 0.12.0
Python version: 3.11.8
Forecaster id: None
# Predict
# ==============================================================================
predictions = forecaster.predict(steps=36)
predictions.head(3)
2005-07-01 0.894926 2005-08-01 0.909836 2005-09-01 1.017546 Freq: MS, Name: pred, dtype: float64