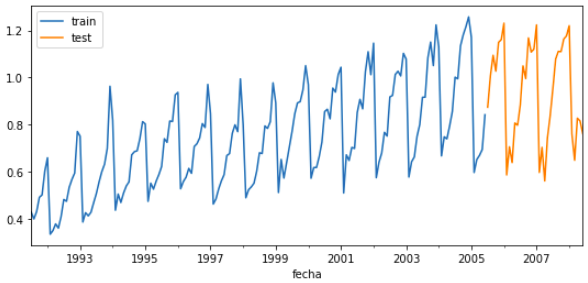
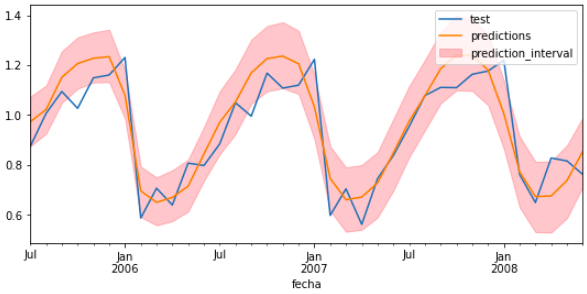
When trying to anticipate future values, the majority of forecasting models try to predict what will be the most likely value, this is call point-forecasting. Although knowing in advance the expected value of a time series is useful in almost every business case, this kind of prediction does not provide any information about the confidence of the model nor the uncertainty in the prediction.
Probabilistic forecasting, as opposed to point-forecasting, is a family of techniques that allow predicting the expected distribution function instead of a single future value. This type of forecasting provides much rich information since it allows to create prediction intervals, the range of likely values where the true value may fall. More formally, a prediction interval defines the interval within which the true value of the response variable is expected to be found with a given probability.
In the book Forecasting: Principles and Practice, Rob J Hyndman and George Athanasopoulos list multiple ways to estimate prediction intervals, most of which require that the residuals (errors) of the model are distributed in a normal way. When this property cannot be assumed, bootstrapping can be resorted to, which only assumes that the residuals are uncorrelated. This is the method used in the Skforecast.
# Create and fit forecaster# ==============================================================================forecaster=ForecasterAutoreg(regressor=Ridge(),lags=15)forecaster.fit(y=data_train)forecaster
1 2 3 4 5 6 7 8 910111213141516
=================
ForecasterAutoreg
=================
Regressor: Ridge()
Lags: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
Window size: 15
Included exogenous: False
Type of exogenous variable: None
Exogenous variables names: None
Training range: [Timestamp('1991-07-01 00:00:00'), Timestamp('2005-06-01 00:00:00')]
Training index type: DatetimeIndex
Training index frequency: MS
Regressor parameters: {'alpha': 1.0, 'copy_X': True, 'fit_intercept': True, 'max_iter': None, 'normalize': 'deprecated', 'positive': False, 'random_state': None, 'solver': 'auto', 'tol': 0.001}
Creation date: 2022-01-02 16:46:14
Last fit date: 2022-01-02 16:46:14
Skforecast version: 0.4.2