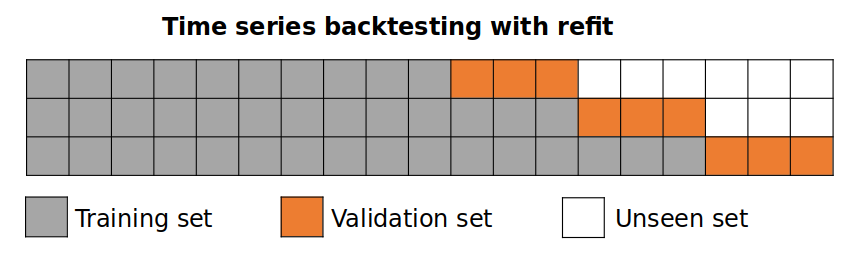
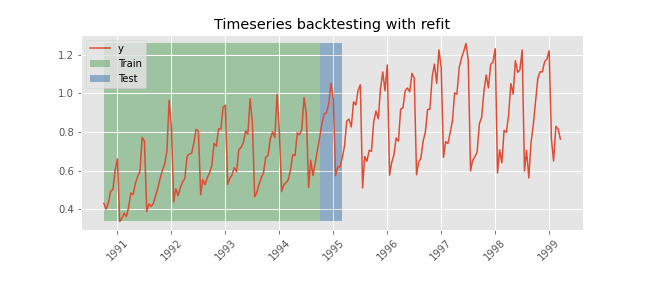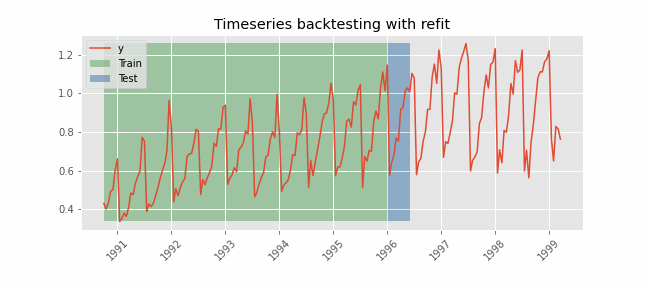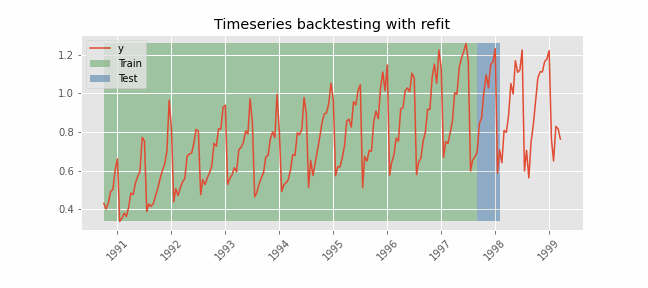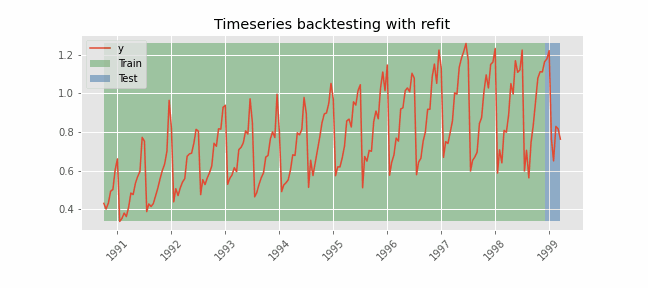
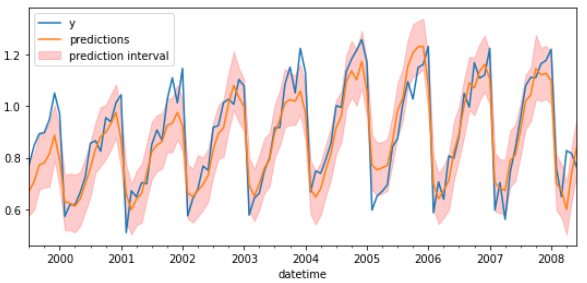
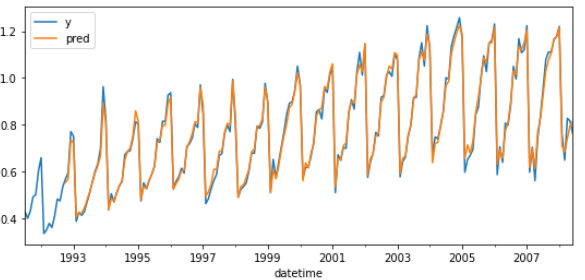
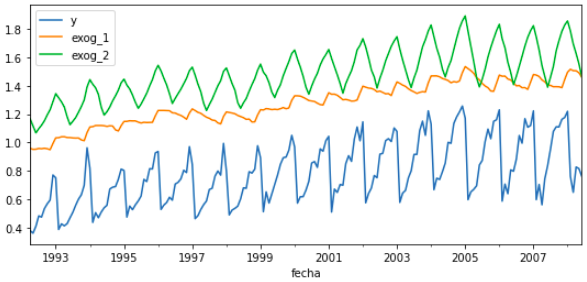
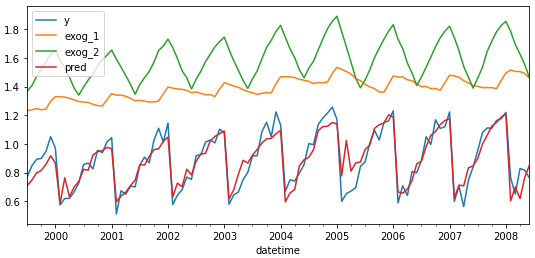
The model is trained each time before making the predictions, in this way, the model use all the information available so far. It is a variation of the standard cross-validation but, instead of making a random distribution of the observations, the training set is increased sequentially, maintaining the temporal order of the data.
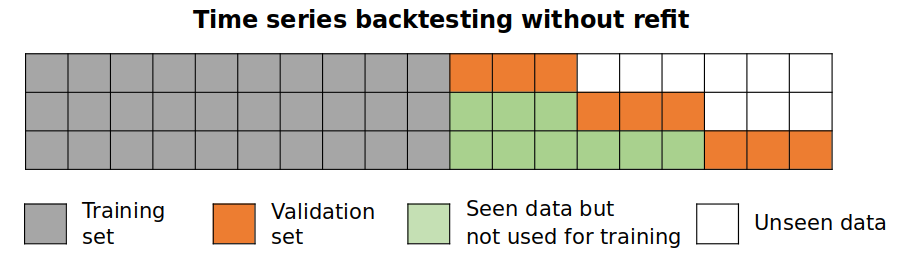
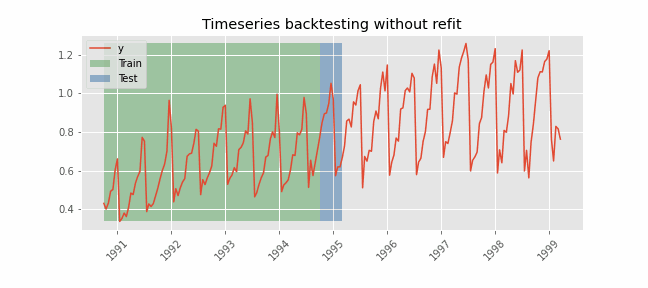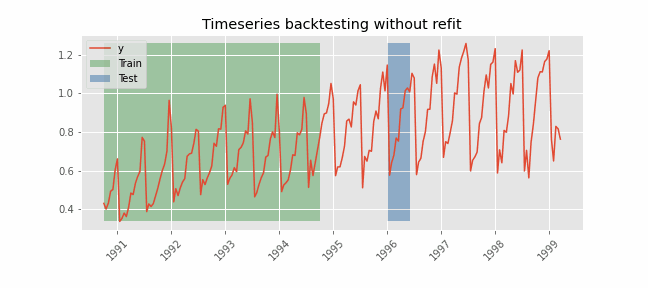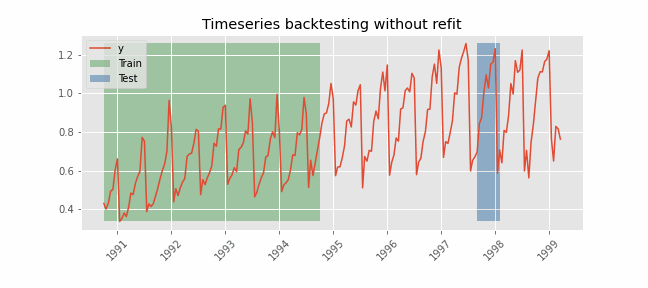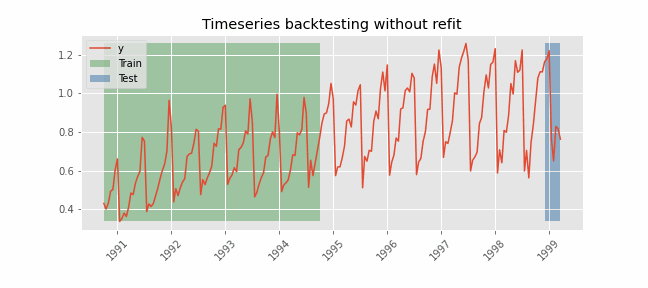
Backtesting without refit
After an initial train, the model is used sequentially without updating it and following the temporal order of the data. This strategy has the advantage of being much faster since the model is only trained once. However, the model does not incorporate the latest information available so it may lose predictive capacity over time.
# Download data# ==============================================================================url=('https://raw.githubusercontent.com/JoaquinAmatRodrigo/skforecast/master/data/h2o.csv')data=pd.read_csv(url,sep=',',header=0,names=['y','datetime'])# Data preprocessing# ==============================================================================data['datetime']=pd.to_datetime(data['datetime'],format='%Y/%m/%d')data=data.set_index('datetime')data=data.asfreq('MS')data=data[['y']]data=data.sort_index()display(data.head(4))# Split data in train and backtest# ==============================================================================n_backtest=36*3# Last 9 years are used for backtestdata_train=data[:-n_backtest]data_backtest=data[-n_backtest:]
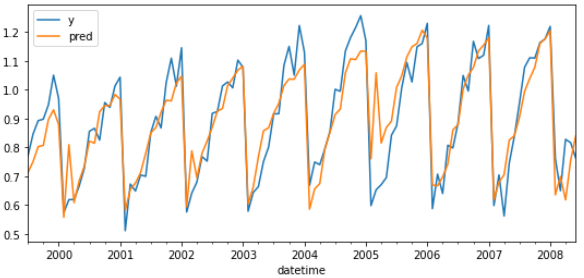
Predictions on training data can be obtained either by using the backtesting_forecaster() function or by accessing the predict() method of the regressor stored inside the forecaster object.
# Fit forecaster# ==============================================================================forecaster=ForecasterAutoreg(regressor=RandomForestRegressor(random_state=123),lags=15)forecaster.fit(y=data['y'])
Set arguments initial_train_size = None and refit = False to perform backtesting using the already trained forecaster.
1 2 3 4 5 6 7 8 910111213
# Backtest train data# ==============================================================================metric,predictions_train=backtesting_forecaster(forecaster=forecaster,y=data['y'],initial_train_size=None,steps=1,metric='mean_squared_error',refit=False,verbose=False)print(f"Backtest training error: {metric}")
Backtest training error: [0.00053925]
1
predictions_train.head(4)
pred
1992-10-01 00:00:00
0.553611
1992-11-01 00:00:00
0.568324
1992-12-01 00:00:00
0.735167
1993-01-01 00:00:00
0.723217
The first 15 observations are not predicted since they are needed to create the lags used as predictors.
123456
# Plot training predictions# ==============================================================================fig,ax=plt.subplots(figsize=(9,4))data.plot(ax=ax)predictions_train.plot(ax=ax)ax.legend();
# Fit forecaster# ==============================================================================forecaster=ForecasterAutoreg(regressor=RandomForestRegressor(random_state=123),lags=15)forecaster.fit(y=data['y'])
123456
# Create training matrix# ==============================================================================X,y=forecaster.create_train_X_y(y=data['y'],exog=None)
Using the internal regressor only allows predicting one step.
123
# Predict using the internal regressor# ==============================================================================forecaster.regressor.predict(X)[:4]
# Download data# ==============================================================================url=('https://raw.githubusercontent.com/JoaquinAmatRodrigo/skforecast/master/data/h2o_exog.csv')data=pd.read_csv(url,sep=',',header=0,names=['datetime','y','exog_1','exog_2'])# Data preprocessing# ==============================================================================data['datetime']=pd.to_datetime(data['datetime'],format='%Y/%m/%d')data=data.set_index('datetime')data=data.asfreq('MS')data=data.sort_index()# Split data in train and backtest# ==============================================================================n_backtest=36*3# Last 9 years are used for backtestdata_train=data[:-n_backtest]data_backtest=data[-n_backtest:]# Plot# ==============================================================================fig,ax=plt.subplots(figsize=(9,4))data.plot(ax=ax);